Translating sqlfluff to rust

TL;DR Sqruff is written in Rust and it's fast (~40x faster on 100 files and ~10x faster for a single file than sqlfluff)
Quary is aiming to build the best Business Intelligence (BI) platform by making engineering practices (CI, version control, preview environments) common to the BI world. Every customer describes their current BI environment as a mess, and we want to help clean things up. The endeavour however can only work if the rigour introduced into BI systems does not slow teams down.
One core building block for these practices is tooling for code quality, linting, formatting, etc. While working with our design partners, we noticed that the current "best in class" SQL linter and formatter Sqlfluff was hampering progress in two main ways:
- It is too slow: In their repositories, it could take minutes to lint the repository in CI.
- It is not portable: We couldn't run it in a browser with the rest of our tooling.
In a bid to solve these issues we rewrote Sqlfluff in Rust, and called it sqruff. This is how we did it, the results, what we learned along the way and what we hope to do next. While we did consider Pyodide, it's performance characteristics were not what we were looking for.
How we did it
Our endeavour to translate sqlfluff didn't start seriously; it was a toy project and an opportunity to play. Over time though we started to believe in its power and prioritise it. Initially, we started translating section by section. We built a dependency tree from the source Python code and worked on it bit by agonising bit. That didn't really work as we ended up wasting time translating tricky, non-critical paths. What ended up being much more productive was the following code. A simple test that we could run to see if the code was working and, over time, work backwards with TODOs. We repeated it over and over again, until we had a working version of the code. The unit test helped to push us along the shortest path to getting something which works, and more importantly, worked quickly.
#[cfg(test)]
mod tests {
use super::*;
fn rules() -> Vec<ErasedRule> {
vec![RuleLT01.erased()]
}
#[test]
fn test_fix() {
let fixed = fix(" select 1 from tbl;", rules());
assert_eq!(fixed, "select 1 from tbl;");
}
}Test-driven development was the key for us. Undertaking the above simple test allowed us to work backwards and build the critical paths for the pieces we required: lexers, parsers, fixers, configuration and rules. It allowed us to work in the most minimal and efficient way possible. The tests directed us and we could just focus on getting the code to work.
Two other good decisions we made early on was not to worry about performance and to translate code as similarly as possible to the source. This allowed us to make sure that we were translating the code correctly and that we didn't introduce any bugs. Along the way, we could also translate smaller unit tests defined in the source Python code that helped us build confidence. This allowed us to get the first end-to-end test working and move on to the next phase of the project, where we started translating the bulk of sqlfluff over to Rust.
With an initial framework for a single rule and dialect in place, we started expanding our work to other rules and dialects. This was an iterative process, and each time we added rules we had to reintroduce some of the complexity present in the original source. It was around this point we started to uncover opportunities for improvement. We made a few tweaks here and there, but it was once the bulk of the code was translated that we really started to optimise the code. These were often pretty simple changes but their impact on the speed of the code was significant. Finally, when things felt stable, we could finally focus on quality and performance.
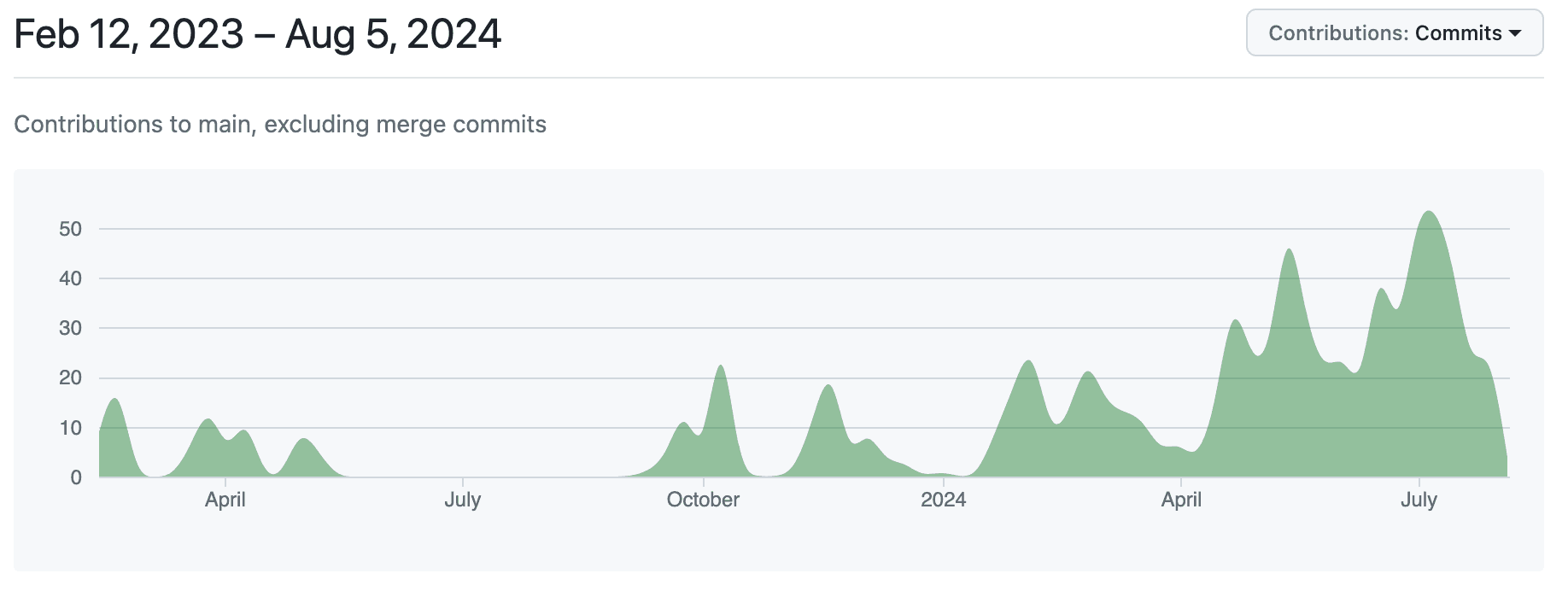
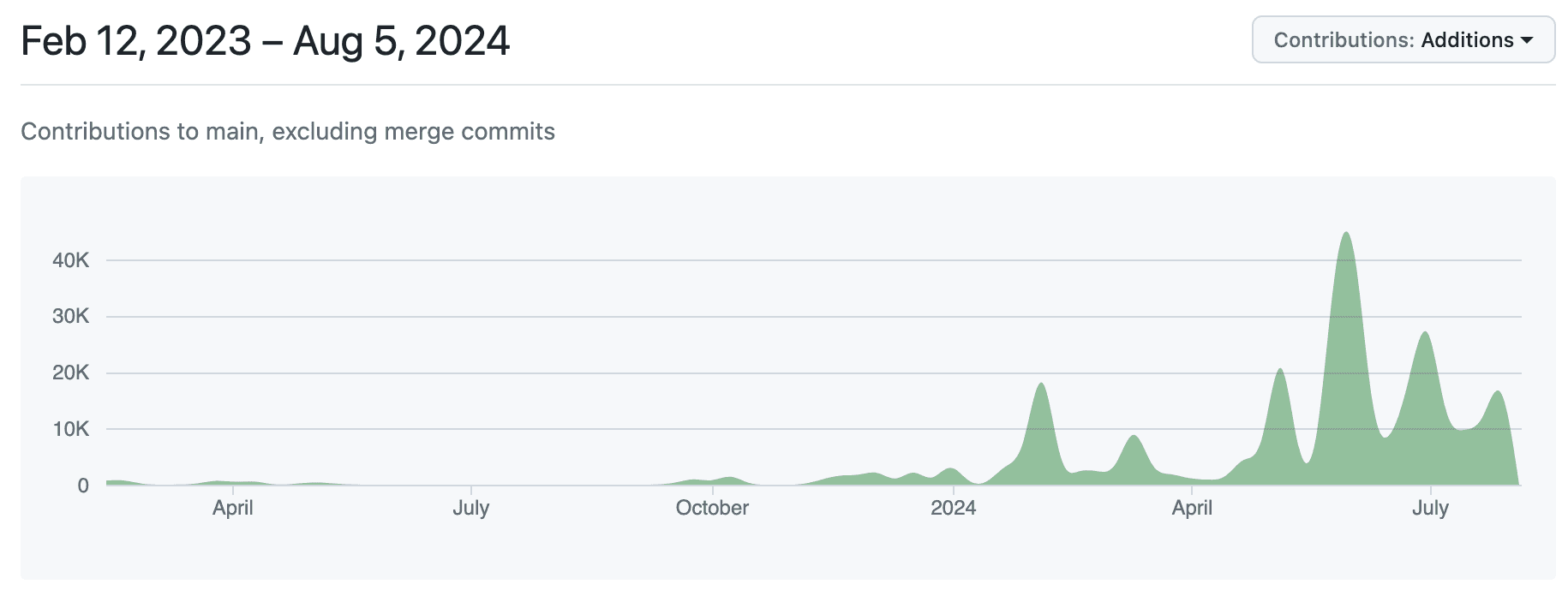
Looking back it's clear these three phases, building the initial structure with TDD, the bulk translation and finally the refinement were crucial in our success. The approach really worked for us and allowed us to build a fast and working version of sqruff. It's also visible from our contribution graphs below that from October, when we started to prioritise the project, we were making lots of small commits as we were pushing the first end-to-end translation. However, once the foundations were set, we could quickly convert lines of code in much larger bulks.
Results
With two of us we translated in about 6 months the bulk of the 100k line code base. Honestly, we're very proud of the results. We were able to make sqruff a near drop-in replacement for sqruff that's 50x times faster than its alternative. It's missing a few features but we're loving using it. The CI we set out to solve initially are gone. The following chart shows the performance of sqruff and sqlfluff in a few different settings:
- Single file linting on a M1 Pro (~10x faster)
- Linting 100 files on a M1 Pro (~40x faster)
- Single file linting in a standard GitHub action (~30x faster)
- Linting 100 files in a standard GitHub action (~35x faster)
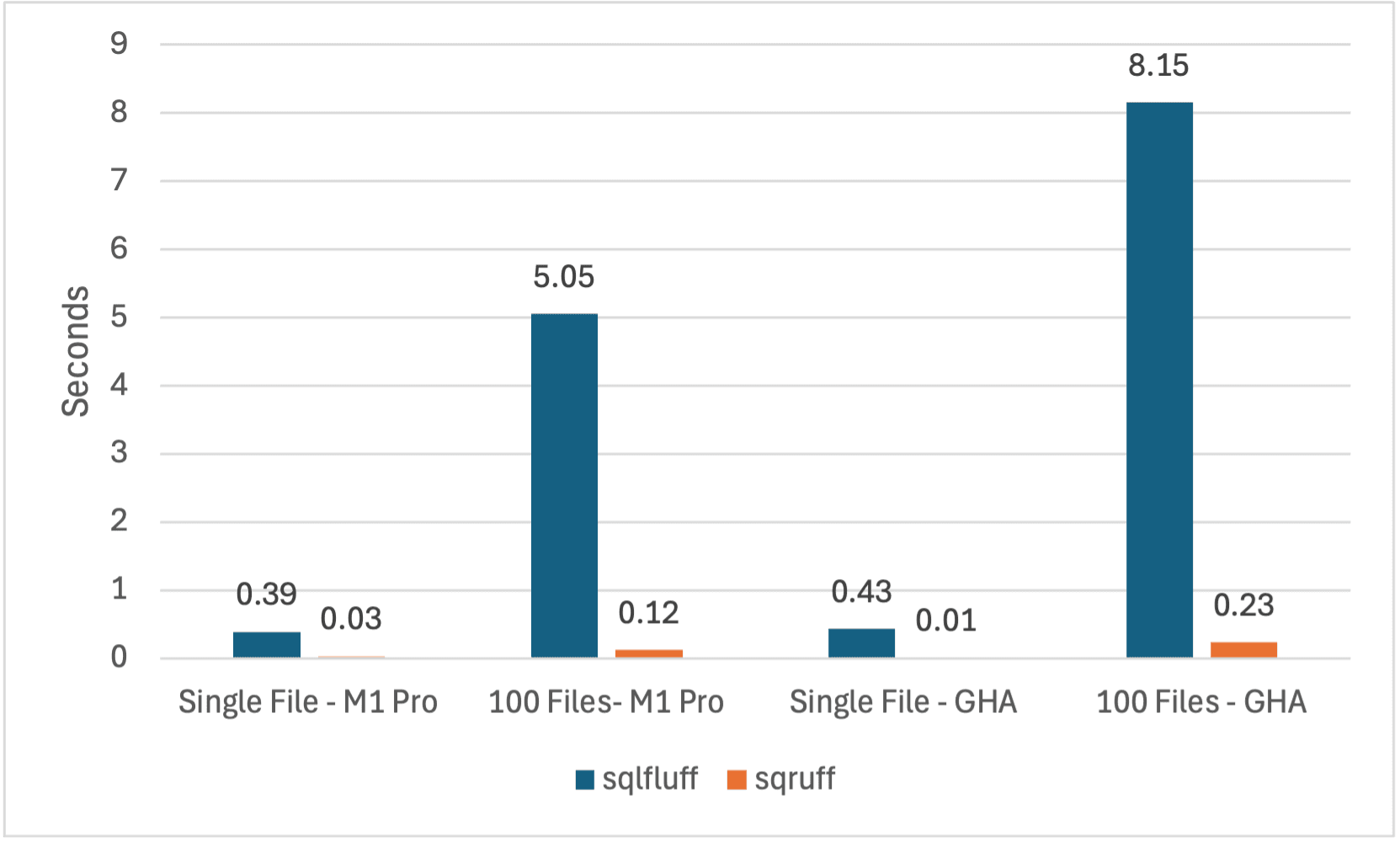
The performance is undeniable and it's clear that we have made the code base significantly faster. For the customers we work with, they saw CI jobs which previously took minutes to run, now takes them only seconds. This is a huge win for us, and for them.
These measurements were taken on the commit 032f0d7 on sqruff on Apple M1 Pro. The version of sqfluff used was 3.0.1. They are measurements of the crates/lib/test/fixtures/dialects/ansi for the 100 files in a folder and crates/lib/test/fixtures/dialects/ansi/select_case_c.sql for a single file.
Optimizations
We made optimisations to our repo over time. Once we had good infrastructure in place for this, we were able to make many small improvements to the code. The infrastructure, in this case, has the ability to run benchmarks and the ability to profile the code. A few of the highlight wins were:
- By benchmarking and finding unnecessary allocations, we were able to make many single digit improvements, including this five line change that made a near 10% improvement in the performance of the code. This was a common pattern and we were able to make many small improvements like this.
- By moving to enums, we were able to make small single digit wins that added up over time. In addition to the small changes, there were also very large wins like this one that made a near 25% improvement. This was a common pattern and we were able to make many improvements like this. In addition to this, we were able to make the code more idiomatic Rust and easier to reason about.
- Sqlfluff uses uuids as its caching mechanisms representation. While it's initially what we ported over to Rust and stored them as strings, we were quickly able to choose better types along the way that gave us high single digit improvements. Better choices, like going from a simple cache counter, rather than generating a UUID, gave us multiple incremental wins.
- Over time, we also got wins by using more appropriate library choices like the JemC allocator which gave us a 15% uplift as well as better hash functions like ahash or int_hash which gave us more small wins.
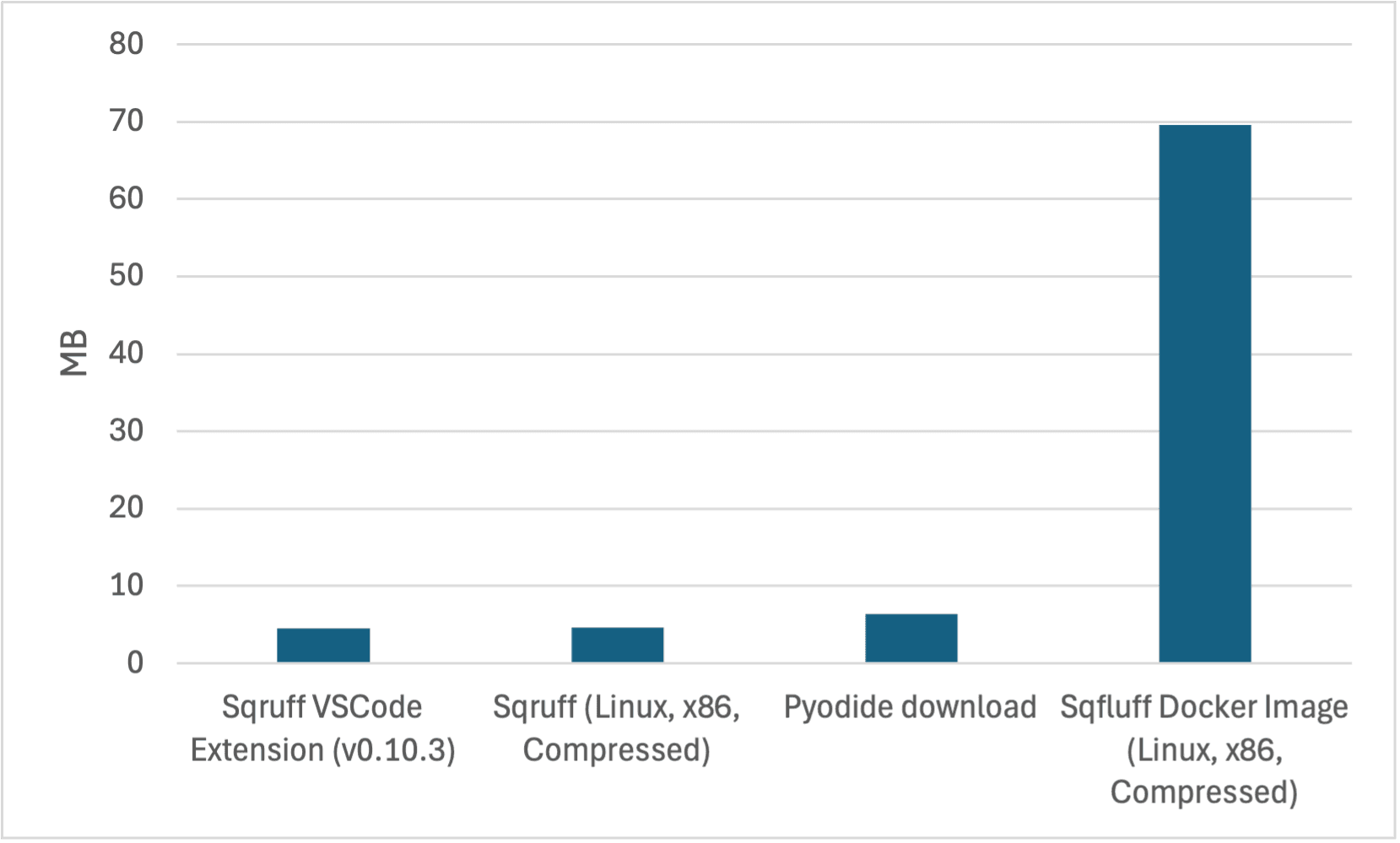
Binary size
Another interesting metric to look at is the size of the binary. While in most scenarios it's not a big deal, in our case, we were looking to package into a WASM binary and into a VSCode extension. The size of the binary was a big deal for us as it has a direct impact on startup time for our customers working in the browser. As shown below, the benefits in this area are also significant, with the sqruff binary being "10x smaller" than the sqlfluff binary.
What we learned
Translating takes time
We were able to build a fast and working version of sqruff but it took more time than we initially anticipated. We started off down the right path. That said, the bit we hadn't quite appreciated at the time, and I would forewarn everyone about, is the time it takes to translate the final bits and polish the code. Codebases have config, edge cases and complexities that have accumulated over time and making sure you consider all of them will take time. It's worth it, but you will have to be patient. This and other projects, like the translation of turbo, should be used as indicators of the time frame.
Rust is fast, easier to reason and easier to optimise
I will come clean and profess my love for Go. It was my tool of choice for my last business and it was great for what we were using for: enterprise web services. That was then, and this is now! One of the things I was amazingly stunned by is Rust's performance, but more so than just it's performance, Rust gives you tools that you can use to improve performance over time. There were many commutes home, where I was able to make incremental improvements to both quality and code, that I would have struggled to do in Go. Benchmarking tooling, enums and the borrow checker all make it easier to reason about the code and improve code quality and performance in tandem. Not only is the code faster, but it's also easier to reason about.
The Unexpected: Performance is weird
We achieved the aim of making sqruff many times more performant than sqlfluff and we learned a lot along the way but what really marked us were the things we didn't expect. When you affect a measure by an order of magnitude, the impact is very difficult to predict and these are the things we didn't foresee.
Simplicity
You can make the performance of sqlfluff feel equivalent to sqruff with little tricks. You can use a caching layer, only check the difference in a pull request or use bigger machines. This is all true, but it's a lot complexity: you have to maintain that cache, you have to worry about that cache interacting with sqlfluff versions and you have to pay for bigger machines.
By making sqruff faster, we made it simpler to use. By taking on higher complexity in our code, we've added performance and taken complexity away from our customers. While you could do the above, you could just use the below Github Action that is way simpler and still probably faster:
jobs:
sqruff-lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: quarylabs/install-sqruff-cli-action@main
- run: sqruff lintChanging how we develop
In our journey, we packaged sqruff into a VSCode extension. I have been using it for a little while now and the biggest surprise has been it changing the way I code. Where my process was to code, add new lines myself and then finally run the linter to fix the code on save, I now just write code and smash CMD+S to format my code as I go. With its performance and by running sqruff in the browser, we've made it easier for developers to stay in the flow.
CI Impact
We initially built sqruff as a CLI to just beat speed and the raw performance of Sqlfluff in a CI setting. We saw jobs take minutes and wanted to get them down to seconds. We saw the sqlfluff lint step take 2.5 mins and thought that should max be a few seconds. We smashed that objective. The interesting thing is that two things became noticeable with our wins:
- Github Actions have a start delay and when your jobs take seconds, that delay becomes quite noticeable.
- We had hoped that our CI cost savings would be proportional to the performance gains. Unfortunately, they were not. Github Actions are billed by the minute and so while we were able to make the jobs faster, we were not able to make them cheaper. This was a bit of a surprise and something we hadn't anticipated.
What's next
While we are certain we will find more performance gains and optimisations, we're looking forward to a few more interesting things we can build on top of sqruff. The first of these changes has been to use sqruff as the foundation of our sqlinference layer in sqruff. sqlinference is a set of functionality we hope to use to deliver.
Shout outs
As much as we built sqruff to improve the performance of sqlfluff, we couldn't have done it without sqlfluff's authors previous work. We were able to do what we did by standing on shoulders of giants. In addition to the authors of sqlfluff, sqruff wouldn't have been possible with the dedication of Andrey.